fio 是一個好用的合成 IO (Synthetic IO Workload) 產生器,我們經常用他來測試例如檔案系統或是 Disk 的 IO 效能等等,他有非常多可調參數,很多時候我們只是複製了某測試的參數就打,這在大多數情況可能是夠用的,但身為一個優秀的效能分析者,我們還是必須要知道 …
- 測試目的?
- 模擬的測試情境?
- 為何使用這組測試參數?
亂選測試參數只會造成 Garbage in, garbage out,結果沒有參考價值,可能還渾然不自知。這篇會介紹幾個常見的測試參數以及他的對應情境,但這些例子並非適用所有情境,某些情境還是需要比較特別的參數設定才適合。
Direct / Buffered
direct 用來指定是否開啟 Direct IO (O_DIRECT),與之對應的是 Buffered IO,兩者在整個 Linux IO stack 有很大差距,在不同測試環境及參數下,很難說哪個數據會較好。這裡主要提供一個測試參數選擇的概略方向,不會在細節上做比較。
Direct IO 與 Buffered IO 最大的差異是有無經過 Memory Management 的 Page Cache,因此從「是否預期 fio HOST 的 Page Cache 會影響 IO Pattern」,來判斷選擇何者是其中一個方式。
如果希望 Page Cache 影響的話選 Buffered IO,不希望的話選 Direct IO。由於 Page Cache 對大多數應用來說都有幫助,若要模擬一般應用過檔案系統的行為,選用 Buffered IO 來模擬通常是較合理的。
另外,由於 Linux 的實作限制,在大部份的情況下 libaio + Buffered IO 會退化成非 AIO 的行為,因此如果發現改 iodepth 仍無法提高平行發下去的 IO 量,也不必太驚訝。
重點注意事項
- libaio + Buffered IO 行為會退化成非 AIO
- 若主要想測試的是 IO Layer,要小心 Buffered IO 相關的測試是否會因為 Page Cache 命中率過高,導致 IO 都打在記憶體上,沒有進到 Block Layer
- Direct IO 因為沒有經過 Page Cache 的關係,所以 Sequential Read 也不會有 Readahead 的行為
- Buffered Write 有將 IO 排序回寫的特性,因此 Buffered Random Write 對於 Disk 來說可能沒有預期中那麼隨機
選 Buffered IO 的例子
- 模擬一般應用對檔案進行讀寫的測試情境:
大多數的情況 Page Cache 都很有用,所以一般應用都是以 Buffered IO 為多,用 Buffered IO 模擬是較合理的
選 Direct IO 的例子
- 待測物是 Disk 的測試:
如果只是想測試單純 Disk 的效能,儘量減少 HOST 的不同對測試結果的影響,可以選擇 Direct IO - 在客戶端對網路伺服器 (例如 Samba Server) 做效能測試
與 Disk 同理,由於測試對象是網路伺服器,不希望 Client 的記憶體影響測試數據 - 需要 libaio 的時候
這是 libaio 的限制 - 模擬部分應用,例如某些 database,使用 Direct IO 模式的行為
libaio / psync
一般最常用的 ioengine 就是 psync 跟 libaio 這兩個,兩者最大的差異就是發送 IO 的方式是屬於同步 (Synchronous),還是屬於非同步 (Asynchronous)。
與 direct 類似,選擇 libaio 還是 psync,主要取決於「是否想要有 Async IO 的特性」,而 Async IO 最主要的目的就是希望提高同時處理的 IO 數量,也就是 Outstanding IO。
提高同時處理的 IO 數量的一種方式是增加 thread 或 job 數,但在 CPU 核心數有限的情況下,thread 數增加到一個程度以後所帶來的開銷會很大,若想要將測試的 Throughput / IOPS 極大化,Async IO 會是有效的選擇。
同時可以發多少筆 Async IO 是由 iodepth 這個參數控制的,在大部分的情況下,若 ioengine 選了 libaio,iodepth 就會是一個想要調整的參數;ioengine 選了 libaio 又將 iodepth 設定成 1,所得到的結果將會接近 psync;相反,若 ioengine 選了 psync,iodepth 的設定通常也就沒有意義。
libaio 雖然很強大,但也是有不少限制,詳細可以參考 Kernel 文件,比較容易遇到的是 (1) libaio + Buffered IO 行為會退化成非 AIO,(2) 不支援 fsync。
另外,由於許多應用的行為會比較接近 psync,若是想模擬一般應用的經過檔案系統的情境時,psync 可能會是一個較佳的選擇,而且 Buffered write 在寫入 Page Cache 後就會返回,行為相對接近非同步,因此 AIO write 非同步的效益也就相對沒有 AIO read 來得顯著。
重點注意事項
- 小心 libaio 的限制,例如 libaio + Buffered IO 行為會退化成非 AIO
- 就算 iodepth 設成 1,libaio 跟 psync 數據仍有可能有些微不同,因為 kernel software stack 不同的關係
選 psync 的例子
- 模擬以同步 IO 為主的應用的測試情境
- 想要測試 fsync
選 libaio 的例子
- 待測物是 Disk 的測試
利用 AIO 以將 Disk 打到飽和 - 在客戶端對網路伺服器 (例如 Samba Server) 做效能測試
與 Disk 同理 - 不想管應用行為,想儘可能打出較高的數據時可以嘗試
jobs / iodepth
jobs (thread) 數及 iodepth 決定了 Outstanding IO 的量,也就是同時間發出去但尚未返回的最大 IO 量。
兩者相乘以後就會得到「從 fio 的角度來看」最大的 Outstanding IO 數,為何說是從 fio 角度來看呢?例如 Buffered write 在 IO 進到 Page Cache 就會返回了,因此對底下的 block device 而言,Outstanding IO 數可能不會是所設定的那樣,在決定測試參數前還是要思考一下整個系統的行為。
Sequential IO 與 numjobs
numjobs 會讓 fio 產生多個 相同行為 的 job。這裡的關鍵是 相同行為 ,例如以下就是一個錯誤的測試範例
fio --numjobs=1 --direct=0 --rw=read --ioengine=psync --bs=64k --group_reporting --name=1 --filename=test_file
# 345 MiB/s
fio --numjobs=2 --direct=0 --rw=read --ioengine=psync --bs=64k --group_reporting --name=1 --filename=test_file
# 690 MiB/s
fio --numjobs=4 --direct=0 --rw=read --ioengine=psync --bs=64k --group_reporting --name=1 --filename=test_file
# 1290 MiB/s
fio --numjobs=8 --direct=0 --rw=read --ioengine=psync --bs=64k --group_reporting --name=1 --filename=test_file
# 2645 MiB/s
不是這個系統的 IO 真有這麼快的速度!
測試數據隨著 numjobs 增加而越來越快,主因是所有 job 都從同一個位置開始順序讀,第一個 thread 將內容從 disk 讀到 cache 以後,剩下的就可以從 cache 讀到資料而不用經過 IO,因此這個測試實際上就是在測記憶體跟 CPU 速度而已。
就算將所有 job 讀的位置錯開,多個 thread 也會造成 disk 收到的 IO 變成在幾個範圍之間跳躍。如果是 Buffered write,page cache 回寫時會協助排序,影響還相對比較小,但如果是 read,就可能導致讀取位置的跳躍頻繁,對 HDD 來說會有極大的差異,測試之前要思考一下這是不是自己想要的。
其他可以搭配的相關參數有 offset_increment、size 等,可以參考 fio 文件說明進行設置。
同步與互斥鎖
多執行緒不可避免的就是同步問題,在 kernel 中當然也是一樣。如果同時有多個 process 對同一個檔案進行讀寫操作,kernel 在獲取該檔案的 inode lock 時的開銷就可能隨著 process 數量增加而變大 (取決於檔案系統實作)。今天如果只是想要極大化測試數據,就可以考慮用多個 job section 讓每個 job 都打在不同的檔案上來迴避,例如以下設定
[global]
group_reporting
...
[file1]
filename=testfile1
[file2]
filename=testfile2
...
該用多少 jobs 及 iodepth
沒有絕對的標準,不同的 jobs 或 iodepth 對應的是不同情境,因此沒有一個絕對的標準說要用多少才合理,但仍然有一些方式可以粗略判斷大概要設定到多少,例如:
- 下層的 queue size 有多大
SATA disk 的 queue size 是 32。如果想要知道極限的話,Outstanding IO 可能只要 32 或略大於 32 就能達到 - CPU 核心數及 CPU 使用率
thread 數比 CPU 核心數大太多的話,context switch 的開銷可能會變重
但就如同前面所說的,不同的參數對應的是不同的情境,取決於想測試的是什麼,不同的 Outstanding IO 代表的是該系統在不同的飽和程度下的效能。可以將不同的 Outstanding IO 對應的 IOPS 都記錄下來畫成類似下圖
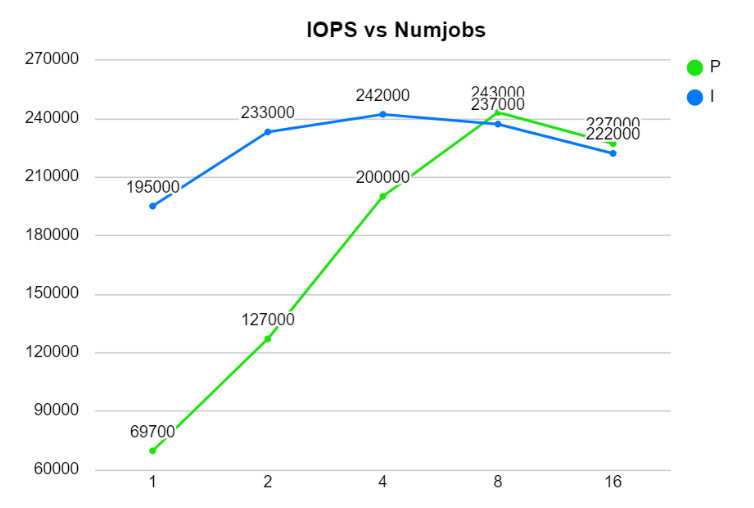
如上圖,I 跟 P 對應的是不同的系統,發現特別的地方了嗎? 這兩個系統的 IOPS 極大值都在 242K 左右,因此標榜的最大 IOPS 很可能差不多,但 I 系統在 thread 數少的情境下,數據是明顯較優的,只靠單一的 spec 數據就不一定可以觀察出這件事。
有些分析方式會將縱軸改成 Latency、橫軸改成 IOPS 來作圖,原理類似只是從不同的面向去看,礙於篇幅這裡就不做解釋,有興趣的可以去找 IOPS、Latency、Little’s Law 相關的文獻。
偶爾會需要注意的參數
預設是 true,如果測試的是 Random IO,在其他參數相同的情況下,會讓每次寫入的 offset 順序相同。
這個參數在大部分情況下沒有什麼問題,但如果需要做多次的循環測試,且待測物重複寫入相同位置的行為,與寫入新位置行為不同,例如快照造成的 copy-on-write、或是一些 cache 等等,這些特性不能在每次測試間重置的情況下,打開 randrepeat 後,測試結果反而會有一點都不 repeat 的驚喜。
先打多久再正式開始統計效能數據前。如果是 Buffered IO 之類的測試,在 page cache 滿或開始回寫的前後,效能數據可能是有差異的,可以使用這個參數來略過前面的時間。
其他部分暫時沒有想到了,如果還有遇到什麼地雷,不時會再回來補充這篇 😄