這篇延續 Linux 系統程式設計 - fd 及 open()、close() 系統呼叫,筆記 read()、write() 系統呼叫及 page cache 相關的部分。內容主要參考 Robert Love 的 Linux System Programming 一書。
read() 系統呼叫
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t len);read() 系統呼叫會從 fd 所參照檔案的當前位置讀取 len 個位元組到 buf,執行成功時會回傳寫進 buf 的位元組數,同時檔案位置也會前進所讀取的位元組數,執行失敗時會回傳 -1 並設定 errno。
雖然 read() 是一個簡單的系統呼叫,但要恰當地進行錯誤處理其實也是相當複雜的,根據不同的狀況,大致上有以下幾種回傳結果:
- 回傳值等於 len: 這是預期的正確結果
- 回傳值等於 0: 表示到了檔案末端 (EOF),沒有資料可以讀取
- 回傳值小於 0: 一般代表發生錯誤,有以下幾種可能:
- errno = EINTR。表示在讀取過程中收到的信號,可以嘗試再讀取一次
- errno = EAGAIN。在 O_NONBLOCK 模式下才會有的情況,表示還沒有資料可以讀取,可以等候一段時間後再嘗試一次
- 其他的 errno。可能是嚴重的錯誤,重試不一定有用
- 回傳值大於 0 但小於 len: 可能是以下三種情況之一,再嘗試讀取一次通常就可以找到真正原因:
- 讀取過程中收到信號中斷
- 讀取過程中發生錯誤
- 可讀取的大小不足 len 或以到達 EOF
EINTR 是比較常被忽視的,他算是高機會可回復的錯誤,如果程式會對信號進行處理的話,應該是需要被考慮處理的錯誤。
write() 系統呼叫
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);write() 系統呼叫會從 buf 中把 count 位元組的資料寫入 fd 所參照檔案的當前位置,執行成功時會回傳寫進入檔案的位元組數,檔案位置也會前進寫入的位元組數,執行失敗時會回傳 -1 並設定 errno。write() 不像 read() 會遇到 EOF,比較不容易發生回傳值不等於 count,但如果 write 的對象是 socket 的話,就仍然要處理只有部分寫入的情況 (回傳小於 count 但大於等於 0)。
lseek() 系統呼叫
#include <sys/types.h>
#include <unistd.h>
off_t lseek(int fd, off_t pos, int origin);lseek() 系統呼叫用來設定檔案的當前位置,本身不會產生任何 IO,成功時會回傳檔案的當前位置,失敗時回傳 -1 並設定 errn。lseek() 的 pos 可以是正、負或是零,實際的行為取決於 origin,可以是以下幾種的其中一個:
- SEEK_CUR: 位置設定為當前位置加上 pos
- pos 是零時可以用來查詢目前檔案位置
- SEEK_END: 位置設定為當前的長度再加上 pos,也就是從結尾開始算的意思
- pos 是零時可以把當前位置設為檔案結尾
- SEEK_SET: 位置設定為 pos,也就是從開頭開始算的意思
- pos 是零時可以把當前位置設為檔案開頭
lseek() 也可以把檔案當前位置設定到檔案結尾以後。此時如果進行讀取的話,會回傳 EOF,若進行寫入的話,中間被跳過的部分會以 hole 的形式填補成 0 而變成 sparse file。
另外 Linux 還有提供了結合 read()、write() 及 lssek() 的變體,他們會從 pos 的位置做讀取或寫入,且完成後不會更動檔案的目前位置,且他也可以避免多執行緒情境下先做 lseek() 再做 read()、write() 可能的 race 情況。
#define _XOPEN_SOURCE 500
#include <unistd.h>
ssize_t pread(int fd, void *buf, size_t count);
ssize_t pwrite(int fd, const void *buf, size_t count);
淺談 Page Cache
Page cache 這東西我一直都是知道但理解很淺,這裡主要整理讀到的相關資料,之後會再找個時間去深入研究核心的程式碼。
Page cache 用來暫存從磁碟上讀起來的檔案系統資料,由於一般硬碟存取速度遠低於記憶體存取速度,因此將資料暫存在記憶體是非常值得的。在尋找檔案系統資料時,核心實際上也是先從 Page cache 尋找,如果不在 cache 中,才會從磁碟中將資料讀取上來。寫入的情況也是,當呼叫 write() 系統呼叫時,核心把資料複製到 page cache 中以後就已經返回了,而這些蒐集到 cache 中的資料會被標記成 dirty,在之後由背景的 flusher 核心執行緒將其寫回 (writeback) 至磁碟中。
和 page cache 相關的參數常見的有以下幾個,位於 /proc/sys/vm/ 目錄底下,這些參數對於 IO 效能及穩定性等會有不小的影響。
- dirty_background_ratio: 當 dirty page 佔用到記憶體的多少百分比時,核心會開始觸發背景寫回
- dirty_background_bytes: dirty_background_ratio 以 bytes 為計算方式的版本,兩者只能指定其中一個
- dirty_ratio: 當 dirty page 佔用到記憶體的多少百分比時,寫入的 IO 會開始遭到阻擋
- dirty_bytes: dirty_ratio 以 bytes 為計算方式的版本,兩者只能指定其中一個
- dirty_writeback_centisecs: flusher 會週期性的被喚醒執行,此為喚醒間隔,單位為百分之一秒
- dirty_expire_centisecs: dirty page 超過該時間後,flusher 被喚醒後就會將其寫回,單位為百分之一秒
- swappiness: 當記憶體不足時,核心傾向選擇將資料搬移到 swap 還是放棄 page cache
- 合法範圍是 0 ~ 100,預設值為 60
- 越高代表越傾向保留 page cache,也就是越容易進行 swap
- 越小則是越容易進行 swap,而越傾向放棄 page cache
Page cache 在一般讀寫情況下都可以運作良好,但有幾個情境會受到影響。首先是系統當掉或是異常斷電,由於 dirty page 還在記憶體中尚未寫入到磁碟的關係,當系統異常斷電時,資料就隨著電力中斷而揮發。另外一種情況是無法安排寫入順序,應用程式可能會有安排的寫入順序,但資料進入到 cache 後,核心會根據效能考量等因素重新安排寫入磁碟的順序,這在一般應用不會受到影響,但某些資料庫系統可能會為了避免資料有不一致的狀態,會期望資料在某些時間能按照某些順序寫入磁碟。這些情況就會需要使用 fsync() 等同步 IO 機制。
fsync()、fdatasync() 及 sync() 系統呼叫
#include <unistd.h>
int fsync(int fd);
int fdatasync(int fd);
void sync();fsync() 會確保 fd 所映射的檔案所有 dirty 的資料及 metadata (中繼資料,如 indoe 包含的時間戳等屬性) 寫回到磁碟中。而 fdatasync() 則會寫回 dirty 的資料及必要的中繼資料,fdatasync() 不保證非必要的中繼資料會寫回到磁碟,因此速度可能會比較快。這兩個函式成功時會返回 0,失敗時返回 -1 並設定 errno。
儘管核心已經要求將資料寫回到磁碟中,且磁碟也回報資料已經寫回,但現今許多的硬碟也都含有自己的寫入快取,因此也不一定真正保證資料已經完全寫入到磁碟。另外這這兩個函式只能保證該檔案的內容已經與磁碟同步,但不包含所屬檔案的目錄,因此如果操作有涉及到目錄的話,還必須連同目錄本身的 fd 調用 fsync() 才能保證異動都寫回磁碟。
sync() 系統呼叫沒有參數也沒有回傳值,他會將所有的 cache 資料都寫回到磁碟。標準並沒有要求 sync() 一定要全部都寫回後才返回,但 Linux 會等到所有緩衝區都寫回才返回。一般不會建議使用 sync(),因為在忙碌的系統上,sync() 有可能會需要數分鐘以上的時間才能完成。
O_SYNC、O_DSYNC 及 O_RSYNC
如果在 open() 時有帶 O_SYNC 旗標的話,則該 fd 所有的 write() 都會進行同步,等效於所有的 write() 返回前都再自動呼叫 fsync()。O_DSYNC 是 O_SYNC 的 fdatasync() 版本。 O_RSYNC 目前被定義成等價於 O_SYNC,他的規範要求是讀取時也必須進行同步,例如讀取時可能會更新資料的 access time,在 read() 返回前也必須同步到磁碟,不過如先前所述,他目前在 Linux 並無實作。
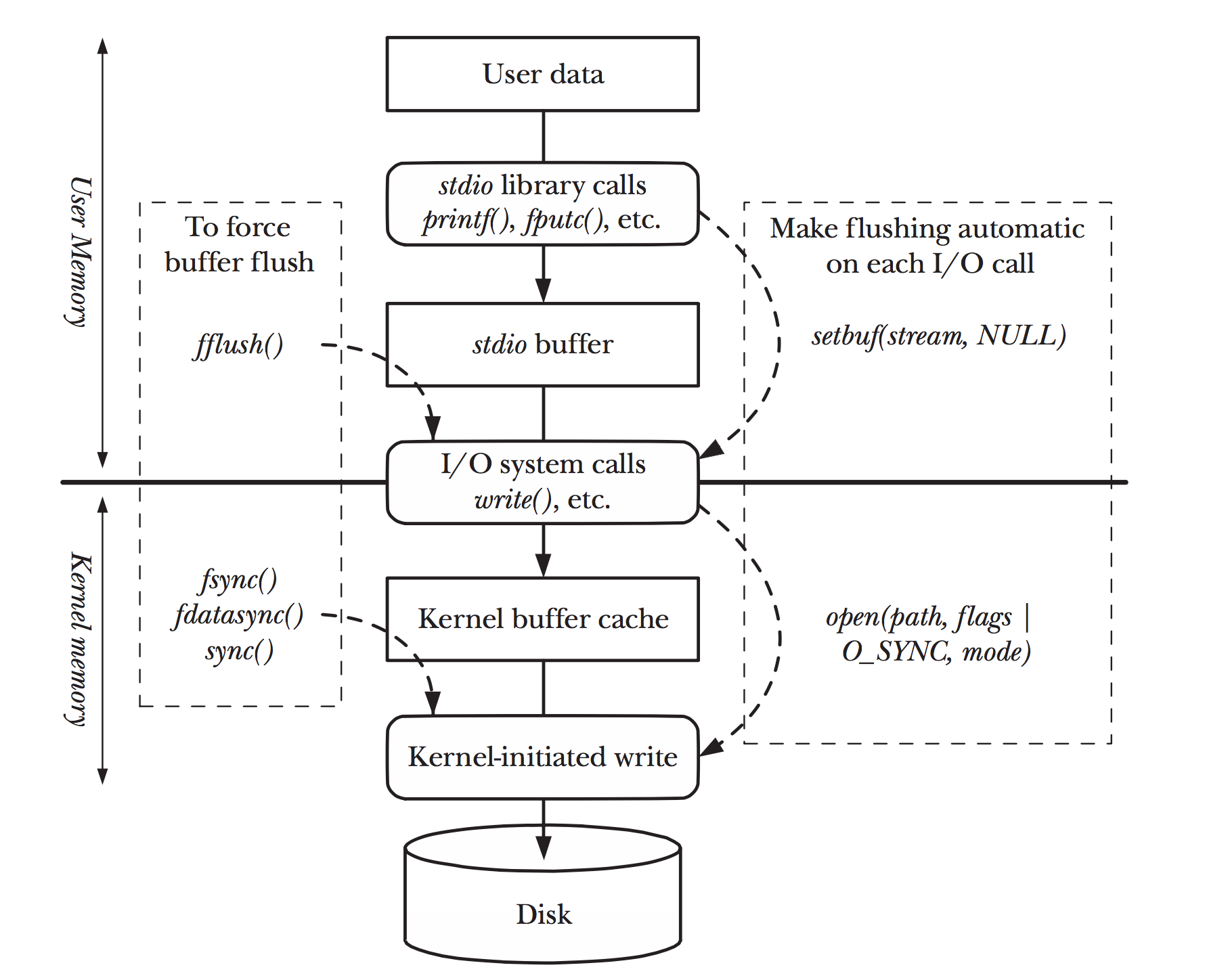
Buffered IO
標準IO函式庫 (stdio) 還實作了一系列 fopen、fread()及fwrite()等函式,與 read()、write() 等系統呼叫最主要的差異是,stdio 在 Userspace 實作了一層 buffer。實作 buffer 的主要原因是 read()、write() 系統呼叫在運作時會需要對齊 block size,對於小於一個 block size 的呼叫,核心仍然會以一個 block size 為單位進行處理,對於較小且未對齊的資料效能會有影響,也會增加不少系統呼叫的次數。
標準IO函式庫的緩衝型式可以在 fopen() 呼叫之後,進行其他操作之前,使用 setvbuf() 函式來進行設定,可以是以下三種的其中一種:
#include <stdio>.h>
int setvbuf(FILE *stream, char *buf, int mode, size_t size);- _IONBF: 無緩衝
- _IOLBF: 以 line 為單位做緩衝,遇到 \n 字元就會提交給核心,可應用於終端機,如 stdout
- _IOFBF: 以 buf 做為緩衝區進行緩衝,大小為 size。若 buf 為 NULL,則會根據 size 自動配置一個
另外還有一個 setbuf() 函式,他等價於 setvbuf(stream, buf, buf ? _IOFBF : _IONBF, BUFSIZE)。
下圖很清楚地說明了 User space buffer 及 Kernel buffer cache (page cache) 之間的關係 (原始出處應該是 Linux Programming Interface 一書)